Digitaalisuus
Pitää luottaa omaan osaamiseensa
Big data (massadata) -analytiikka on käsite, joka kiinnostaa sekä yrityksiä, opiskelijoita että opettajia. Tämän osoittaa mm. se, että opettamani Big Data -kurssi on joka kevät ääriään myöten täynnä, eikä kaikkia halukkaita edes voida ottaa mukaan kurssille, kirjoittaa Lili Aunimo.
Yritysten edustajien kanssa keskustellessa käy ilmi, että big data -analytiikkaan ollaan valmiita investoimaan, sillä siihen tehtyjen investointien uskotaan maksavan itsensä moninkertaisesti takaisin. Olemme tänä syksynä Haaga-Heliassa selvittäneet myös opettajien näkemystä siitä, mitä digitaalisuuteen ja sisällöntuotantoon liittyvää osaamista he tahtoisivat kehittää. Massadatan analysointi nousi tässäkin kyselyssä kärkisijoille.
Koska big data -analytiikka siis herättää näinkin paljon kiinnostusta, on syytä selvittää, mistä pohjimmiltaan on kyse. Onko big data -analytiikka todella jotakin uutta vai voitaisiinko sen lupaukset lunastaa soveltamalla tilastollisen analyysin menetelmiä? Tämä olisi mielenkiintoista tietää; tilastollisten menetelmien kursseilla ei nimittäin ole näkynyt minkäänlaista opiskelijavyöryä. Yrityksetkään eivät ole lisänneet investointejaan tilastollisen analyysin menetelmien soveltamiseen ja käyttöönottoon, eivätkä opettajatkaan ole perustaneet kyseisen aiheen ympärille osaamisen jakamisen ryhmiä.
Big data (massadata) on termi, jonka käyttö on yleistynyt jyrkästi sitten vuoden 2010 (ks. kuvio 1). Massadata on dataa, jota on paljon, joka on heterogeenista ja/tai joka liikkuu. Tätä kutsutaan massadatan kolmen V:n määritelmäksi: volume (massa), variety (monimuotoisuus eli heterogeenisyys) ja velocity (nopeus eli liikkuvuus) (Liebowitz 2014, Tache 2016). Usein massadataksi hyväksytään data, jossa edes yksi yllä mainituista ominaisuuksista täyttyy. Tiukimmat koulukunnat vaativat, että kaikki kolme ominaisuutta täyttyvät, jotta kyseessä olisi massadata.
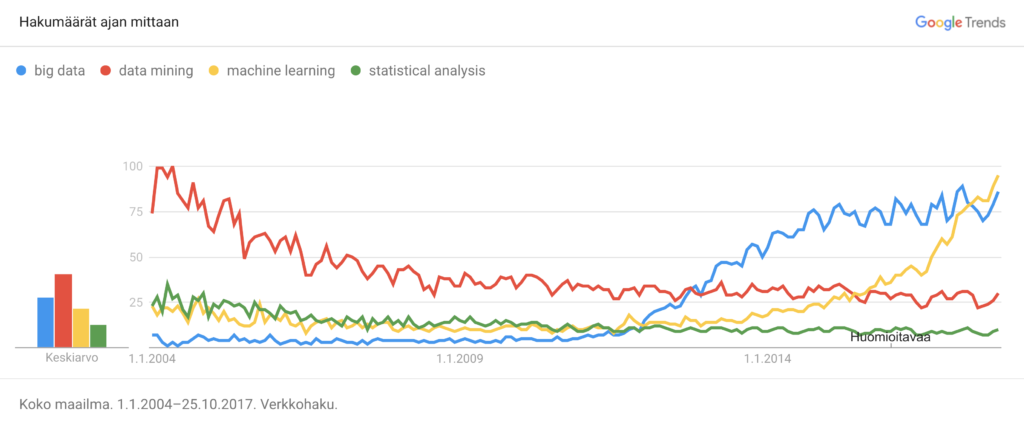
Massadata ei siis aina välttämättä sisällä tera- tai petatavuja dataa. Se voi myös olla dataa, joka on monessa eri muodossa kuten tekstinä, kuvina tai äänenä. Tai vaihtoehtoisesti se voi olla liikkeessä olevaa dataa, kuten erilaisista sensoreista jatkuvasti tulevaa mittausdataa tai Twitter-uutisvirtaa. Big data -analytiikka on joukko menetelmiä, jotka on kehitetty nimenomaan suurten, heterogeenisten ja liikkuvien datojen analysointiin.
Analytiikka taas on sellaista data-analyysiä, jota tehdään yrityksen tai organisaation liiketoiminnan tarpeisiin. Analytiikan juuret ovat liiketoimintatiedon hallinnassa ja analysoinnissa (business intelligence). Data-analyysi taas on laajempi termi ja se sisältää myös muuhun tarkoitukseen tehtyä data-analyysiä, kuten tieteellistä tutkimusta varten tehdyt data-analyysit.
Tilastollinen analyysi on termi, jonka käyttö ja suosio on vakiintunutta, kuten kuviossa 1 näkyy. Sen menetelmät ovat perustana sekä liiketoimintatiedon analysoinnissa, että tieteellisessä kvantitatiivisessa tutkimuksessa. Tilastolliset menetelmät ovat myös perustana monille big data -analytiikan menetelmille. Tilastollisella analyysillä ja big data -analytiikalla on kuitenkin iso joukko merkittäviä eroavaisuuksiakin. Alla on listattu viisi tärkeintä eroavaisuutta, joista kolme viimeistä liittyvät massadatan kolmen V:n määritelmään.
Palataanpa alkuperäiseen kysymykseemme: onko big data -analytiikka tullut jäädäkseen vai onko se vain uusi termi tilastolliselle analyysille?
Vaikka big data -analytiikka perustuu jo pitkään käytettyihin menetelmiin kuten tilastolliseen analyysiin, tiedon louhintaan ja koneoppimiseen, voidaan sitä pitää kuitenkin myös jonain uutena ja pysyvänä. Tämän takaa jo se, että yhteiskunnan digitalisoituminen aiheuttaa vääjäämättä datan määrän kasvun. Tämä data on pitkälti heterogeenista, ja osa siitä on nopeasti päivittyvää.
Kuten tietojenkäsittelytieteessä usein käy, on tarve big data -analytiikalle lähtöisin alan yrityksistä, ei akateemisista lähtökohdista. Esimerkkinä tästä on Alibaba-verkkokauppa, jonka rakentama Galaxy-alusta pystyy käsittelemään viisi miljoonaa transaktiota sekunnissa ja prosessoimaan kaksi petatavua dataa päivässä (Jin ym. 2015). Yritysvetoisuuden takia big data -analytiikkaan liittyvät termit ovat alussa olleet vakiintumattomia ja sisältäneet ylisuuria odotuksia. Nyt tilanne on big data -analytiikan osalta tasaantumassa, ja huomaamme, että kyseessä on pysyvä ilmiö, joka on huomattavasti laajempi kuin pelkkä tilastollinen analyysi.
Lähteet